A l’extérieur de votre organisation est le
chaos, les technologies naissent et meurent en fonctions de facteurs
incontrôlés et
incontrôlables (les effets de mode, la réglementation en vigueur, la volatilité des marchés, etc.).
A l’intérieur de votre organisation règne l’
ordre, la
maîtrise technologique, mais c’est aussi le royaume du « legacy-qui-marche-bien-pourquoi-on-le-changerait ». L’
obsolescence des applicatifs vous guette, vous êtes fan des nouvelles technologies mais l’entropie de votre organisation ressemble à des sables mouvants qui ensevelissent toute action pour tenter d’y échapper. Comment alors stabiliser la technologie alien qui serait propre à sauver votre organisation de la décrépitude numérique ?
Il existe pour cela la méthode des Technology Readiness Levels (TRLs) pour vous sauver. C’est une méthode qui permet d’évaluer une technologie nouvelle pour la qualifier apte à supporter le développement de vos nouveaux produits.
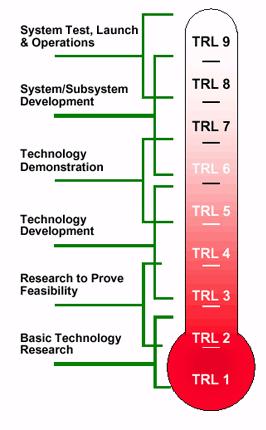
Voici les degrés d’avancement de la méthode (Origine: DOD (2006), Defense Acquisition Guidebook) :
- TRL 1: Principes de base observés et signalés
- TRL 2: Concepts et/ou applications de la technologie formulés
- TRL 3: Fonction critique analysée et expérimentée et/ou « proof-of-concept » la caractérisant
- TRL 4: Validation de l’artefact produit en conditions expérimentales
- TRL 5: Validation de l’artefact produit en conditions de pré-production
- TRL 6: Démonstration du modèle du système/sous-système ou du prototype en conditions de pré-production ou de production
- TRL 7: Démonstration du prototype du système en conditions de production.
- TRL 8: Complément du système résultant et « qualification » pour la production à travers des tests et des démonstrations (environnement de pré-production ou production)
- TRL 9: Exécution du système résultant « prouvée » à travers le succès de la version en production
Plus on avance dans la méthode et moins on doit avoir de technos candidates qui passent les conditions nécessaires. C’est un peu comme cela que fonctionnent les organismes de recherche qui ne font pas aboutir toutes leurs recherches avec une application fonctionnelle et encore moins industrialisable.
Cette méthode a été développée par la NASA. J’ai adapté les termes à un produit logiciel. Par exemple, citons cette analogie : leur environnement de pré-production est le sol et celui de production de l’espace. Je pense que si c’était le cas en informatique, il y aurait sûrement plus de candidats à aimer la prod…
Ce processus est « outillé ». Un calculateur d’avancement réalisé avec Excel permet de suivre l’avancement au sein de la méthode. Attention, les couleurs piquent un peu les yeux… On peut décider de s’évaluer au choix avec le TRL, le Manufacturing Readiness Level et les Programmatic Readiness Level. Cela ajoute plus ou moins de questions au formulaire pour calculer l’avancement.
Voici la fiche de ce
programme excel à télécharger (et sa
documentation pdf - 16 pages)

Cette méthode est utilisée dans la société de ma mission actuelle comme base au processus de travail de l’équipe R&D. Ils ont des jalons à chaque degré avec des documents types à produire. Cette méthode qui a fait ses preuves aide effectivement à atteindre l'objectif qu'elle se fixe. On ne peut malheuresement pas tout rendre agile. Par contre l'agilité peut permettre de gagner en rapidité sur les "proof-of-concept" ce qui peut augmenter la taille de l'échantillon des technologies candidates et ainsi renforcer la fiabilité et la pertinence du choix final.







{kind=link}
{kind=link}